Attention Mechanism in Generative AI
- Jun 19, 2023
- 3 min read
Presenter: Sanjana Reddy, Machine Learning Engineer at Google's Advanced Solutions Lab

1. Transformers
Transformers: A groundbreaking deep learning architecture introduced by Vaswani et al. in the paper "Attention is All You Need" (2017)
Origin: Developed to address the limitations of recurrent neural networks (RNNs) and convolutional neural networks (CNNs) in natural language processing (NLP) tasks
Key innovation: The attention mechanism, which allows the model to focus on different parts of the input sequence and capture long-range dependencies more effectively
Advantages: Better handling of long sequences, improved parallelization, and faster training compared to RNNs and CNNs
Applications: Transformers have become the foundation for state-of-the-art NLP models like BERT, GPT, and T5, and are used in various tasks such as machine translation, text summarization, and sentiment analysis

2. Encoder-Decoder in Translation
Example: Translating an English sentence to French
Encoder-decoder model: A popular model used for translation, which takes one word at a time and translates it at each time step
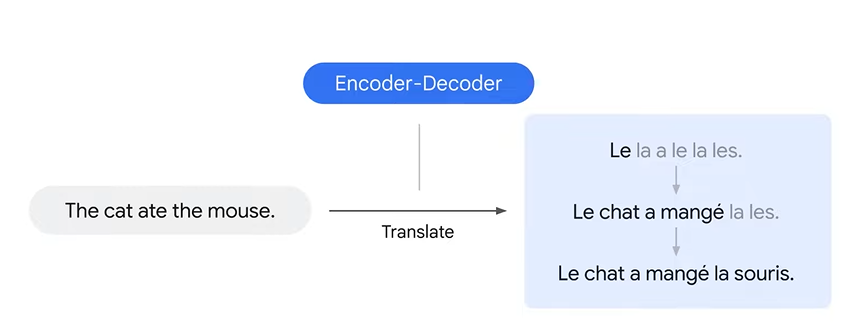
Limitation: Words in source and target languages may not align, causing translation issues. For instance, the order of adjectives and nouns may differ between languages, leading to incorrect translations.
3. Attention Mechanism
Goal: Improve model's focus on important parts of the input sequence and address the limitations of the traditional encoder-decoder model

Technique: Assigns weights to different parts of the input sequence, with higher weights for more important parts. This allows the model to selectively focus on the most relevant information in the input when generating the output.
Comparison: Traditional RNN-based encoder-decoder vs. attention model. The attention model incorporates an additional step that refines the focus on the input sequence during the translation process.
Attention Mechanism Example
Translation example: "Black cat ate the mouse" in English to French
Result: Better translation with the attention mechanism, focusing on important words during translation. The attention model can correctly align the French word "chat" (cat) with the English word "cat," even though the order of the words is different.
4. Attention Model Differences
More data passed to the decoder: Encoder passes all hidden states from each time step, giving the decoder more context. This allows the decoder to have a better understanding of the overall input sequence, rather than just relying on the final hidden state.
Extra step in the attention decoder: Focuses on the most relevant parts of the input before producing its output. This helps the model to generate more accurate translations by taking into account the relationships between words in the input sequence.


5. Attention Decoder Steps
Look at the set of encoder states received: The decoder examines the encoder hidden states, each associated with a word in the input sentence.
Assign a score to each hidden state: The decoder calculates a score for each encoder hidden state based on its relevance to the current output word.
Multiply each hidden state by its softmax score: The decoder amplifies high-scoring states (more relevant) and downsizes low-scoring states (less relevant). This helps the model to focus on the most important aspects of the input sequence.

6. Attention Mechanism in Encoder-Decoder Architecture
Calculate a context vector: Compute a weighted sum of encoder hidden states and the decoder hidden state. This vector represents the most relevant information from the input sequence for the current output word.
Concatenate the decoder hidden state and the context vector: Combine the context vector with the current hidden state of the decoder, forming a more comprehensive representation of the information needed for generating the output word.
Pass the concatenated vector through a feedforward neural network: Use this neural network, which is trained jointly with the model, to predict the next word in the output sequence based on the concatenated vector.
Continue until the end-of-sentence token is generated: Repeat the above steps for each output word until the decoder generates the end-of-sentence token, signaling the completion of the translation process.

Attention Network Notations
Alpha (α): Attention weight at each time step, representing the importance of each input word for generating the current output word
H: Hidden state of the encoder RNN at each time step, representing the information extracted from the input sequence
B: Hidden state of the decoder RNN at each time step, representing the information generated so far in the output sequence
7. Conclusion
Attention mechanism improves the performance of traditional encoder-decoder architectures in generative AI models by addressing the alignment issue and allowing the model to focus on the most relevant parts of the input sequence when generating the output. This results in more accurate and contextually appropriate translations.
Check out the complete video lecture here :
Did you find this useful ?
Yes
No



Comments