Create Image Captioning Models: Overview
- Jun 19, 2023
- 3 min read
Presenter: Takumi Ohyama, Machine Learning Engineer at Google's Advanced Solutions Lab

1. Image Captioning Task and Dataset
The goal is to build and train a model that can generate captions based on input images. A dataset containing pairs of images and text data is used for this purpose.
2. Encoder-Decoder Model

The model is designed as an encoder-decoder architecture where the encoder and decoder handle different modalities of data (image and text). The encoder extracts information from images, creating feature vectors that are passed to the decoder. The decoder then generates captions one word at a time.
Encoder
The encoder can use any image backbone like ResNet, EfficientNet, or Vision Transformer. The goal here is to extract features using these backbones.


Decoder
The decoder architecture is more complex. It processes words one by one, combines information from words and images, and predicts the next word. A transformer-like architecture is built, although an RNN-like structure is still used.


Components of the Decoder
Embedding Layer: Creates word embeddings, which are passed to the next layer.
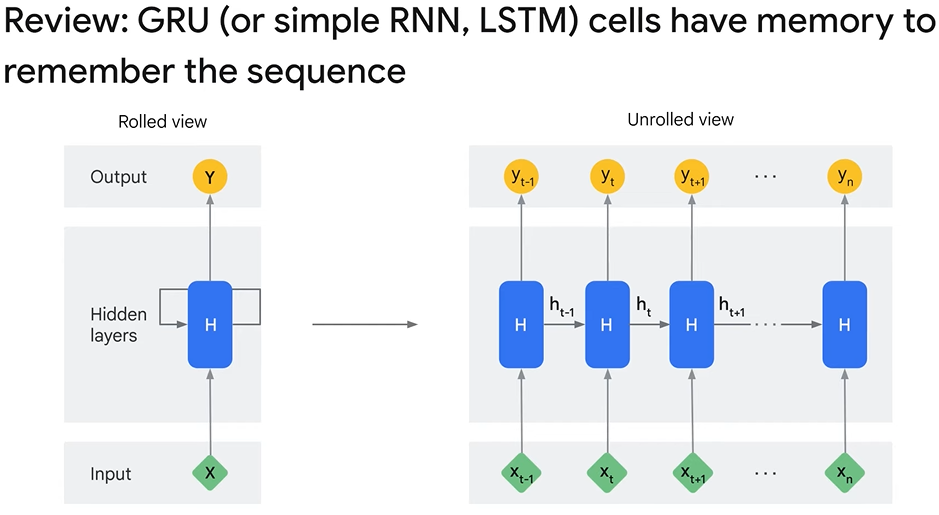
GRU Layer: A variation of the Recurrent Neural Network (RNN) that takes inputs, updates its internal states, and generates output. It processes sequential data like text and keeps track of dependencies from previous inputs.
Attention Layer: Mixes information from text and image. The predefined attention layer from TensorFlow is used here.
Add Layer and Layer Normalization: Adds two same-shape vectors. The output of the GRU layer is passed to the attention layer and directly to the add layer. These two flows are merged in the add layer.




The architecture uses a skip connection (also called residual connection), which is a popular design pattern in deep neural networks since the introduction of ResNet. It is especially useful for designing deep neural networks and is also used in transformers.
3. Training the Model
The encoder-decoder image captioning model is trained using the captioning dataset.
4. Inference Phase

The inference phase involves generating captions for unseen images. The following steps are implemented in a custom inference function:
Initialize the Initial State and Create a Start Token: At the beginning of each captioning, the state is initialized with some value, and a start token is used as the first input word for the decoder.

Pass Input Image to Encoder: The feature vector is extracted by passing the input image to the encoder.

Pass the Vector to the Decoder: A caption word is generated in a for loop until it returns an end token or reaches the maximum caption length. This involves calling the decoder iteratively and passing three inputs: decoder inputs, current state, and image features.

This simple text generation model is similar to large language generation models like Google's BERT.
Python notebook for Image Captioning with Visual Attention The notebook contains all the steps to build and use an image captioning model.
First, the model imports the necessary libraries like TensorFlow and Keras. These are machine learning frameworks that allow you to build neural networks.
The model defines hyperparameters like the size of the word vocabulary it will use and which pre-trained image model it will use (InceptionResNetV2) to extract image features.
The model then loads the COCO Captions dataset which contains images and corresponding captions. It prepares the data by preprocessing the images and captions.
The model then adds special "start" and "end" tokens to the captions. This helps define the beginning and end of each caption.
The model uses a "tokenizer" that converts words into numeric indexes. This allows the model to use the words as input.
The model then creates a "dataset" by applying a function that returns the image data and corresponding caption. The "target" or label is created by shifting the caption by one word.
The model has two main parts: an "encoder" that uses InceptionResNetV2 to extract image features, and a "decoder" with layers like embedding, GRU and attention that generates the caption word by word.
The model defines a "loss function" to account for padded data in the captions.
Training the model takes 15-20 minutes on a powerful GPU.
For generating captions, a separate decoder is created to control the GRU state. The model generates one word at a time based on this state. Words are chosen stochastically from the word probabilities.
The generated captions for sample images are meaningful though not perfect, showing the model has learned to describe images. This demonstrates how a simple encoder-decoder generative model can be built.
Check out the complete video lecture here :
Did you find this useful ?
Yes
No



Comments