Encoder-Decoder Architecture in Generative AI
- Jun 16, 2023
- 2 min read
Updated: Jun 19, 2023
Presenter: Benoit Dherin, Machine Learning Engineer, Google Advanced Solutions Lab

1. Overview
This lecture focuses on the encoder-decoder architecture, which is at the core of large language models. The main topics covered are:
Brief overview of the encoder-decoder architecture
Training process for these models
Generating text from a trained model at serving time
2. Introduction to Encoder-Decoder Architecture
Sequence-to-sequence architecture
Takes a sequence of words as input (e.g., a sentence in English) and outputs a sequence of words (e.g., the translation in French).
Examples include translation, text summarization, and dialogue generation.

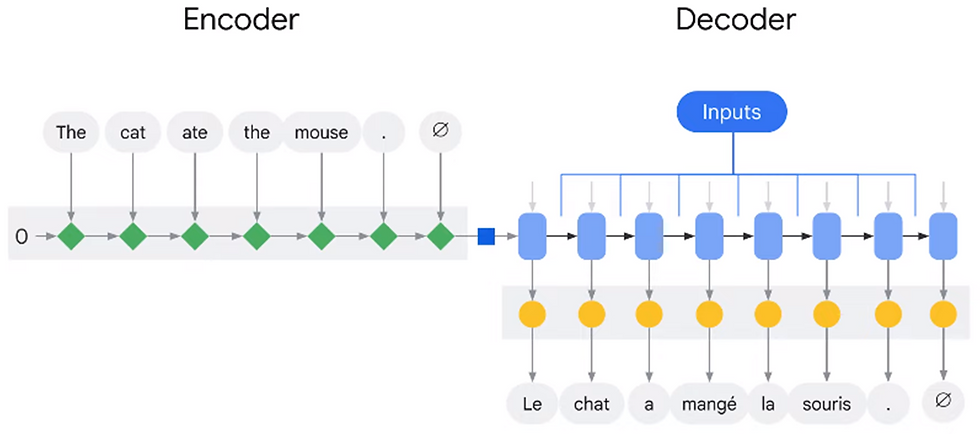
Encoder
Processes the input sequence and produces a vector representation of the input sentence.
Can be implemented with various internal architectures, such as a Recurrent Neural Network (RNN) or a more complex Transformer block.
In an RNN encoder, each token in the input sequence is processed one at a time, producing a state representing the token and previously ingested tokens. The state is then used as input for the next encoding step, along with the next token.
Decoder
Takes the vector representation of the input sentence from the encoder and generates an output sequence.
Can also be implemented with different internal architectures, like RNN or Transformer block.
In an RNN decoder, the output is decoded one token at a time using the current state and what has been decoded so far.
3. Training Encoder-Decoder Models
Training dataset
A collection of input/output pairs that the model should imitate.
For translation, this would include sentence pairs in the source and target languages.
Training process
Feed the dataset to the model, which adjusts its weights during training based on the error it produces for a given input.
The error is the difference between the model's generated output and the true output sequence in the dataset.
Teacher forcing
During training, the decoder needs the correct previous translated token as input to generate the next token, rather than what the decoder has generated so far.
Requires preparing two input sentences: the original one fed to the encoder and the original one shifted to the left, fed to the decoder.

4. Generating Text at Serving Time
Text generation process
Feed the encoder representation of the prompt to the decoder along with a special token (e.g., "GO").
The decoder generates the first word by taking the highest probability token with greedy search or the highest probability chunk with beam search.
Repeat this process for subsequent words until the output sequence is complete.
# Greedy search vs. beam search
Greedy search: Select the token with the highest probability.
Beam search: Use probabilities generated by the decoder to evaluate the probability of sentence chunks rather than individual words. Keep the most likely generated chunk at each step.
Check out the complete video lecture here :
Did you find this useful ?
Yes
No



Comments