Introduction to Image Generation with Diffusion Models
- Jun 15, 2023
- 3 min read

Presenter: Kyle Steckler, Machine Learning Engineer, Google Cloud Advanced Solutions Lab
1. Overview
This talk provides an introduction to diffusion models, a family of models that have shown great promise in the image generation space.
Promising Image Generation Approaches
Variational Autoencoders (VAEs): These models encode images to a compressed size and then decode back to the original size while learning the distribution of the data itself. VAEs can generate new images by sampling from the learned distribution.
Generative Adversarial Models (GANs): GANs pit two neural networks against each other: a generator that creates images and a discriminator that predicts if an image is real or fake. As the discriminator improves at distinguishing real from fake images, the generator becomes better at creating realistic fakes. This concept has led to the creation of deep fakes.
Auto-regressive Models: These models generate images by treating them as sequences of pixels. Modern approaches draw inspiration from how large language models (LLMs) handle text, predicting pixels based on the context of previously generated pixels.
2. Diffusion Models
Background
Diffusion models are inspired by physics, specifically thermodynamics.
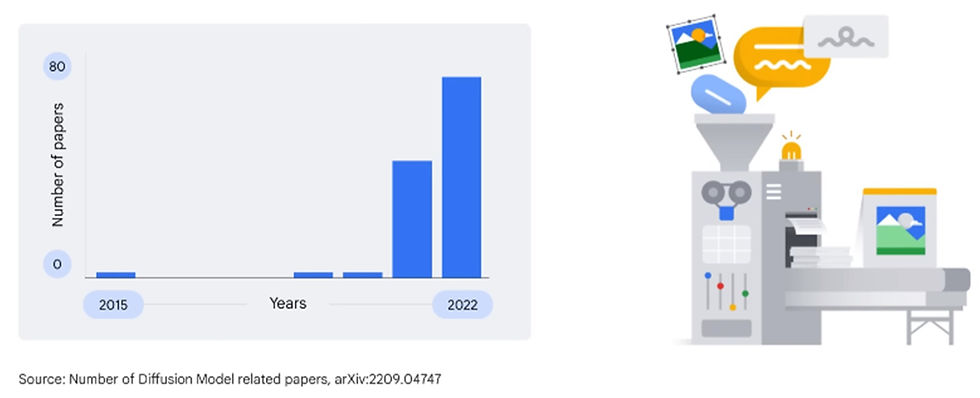
They were first introduced for image generation in 2015, but their potential was not immediately recognized.
Since 2020, diffusion models have gained popularity in both research and industry, underpinning state-of-the-art image generation systems.
Use Cases

Unconditioned Diffusion Models:
Generate new images of a specific subject (e.g., faces) by training on a dataset of images of that subject.
Perform super-resolution tasks to enhance low-quality images by learning the distribution of high-quality images and applying it to the low-quality input.
Conditioned Generation Models:
Generate images from text prompts by conditioning the model on the text input.
Perform image inpainting to fill in missing or corrupted parts of an image by conditioning the model on the available image data.
Execute text-guided image-to-image editing by conditioning the model on both the input image and the text prompt.
3. How Diffusion Models Work
Forward Diffusion Process
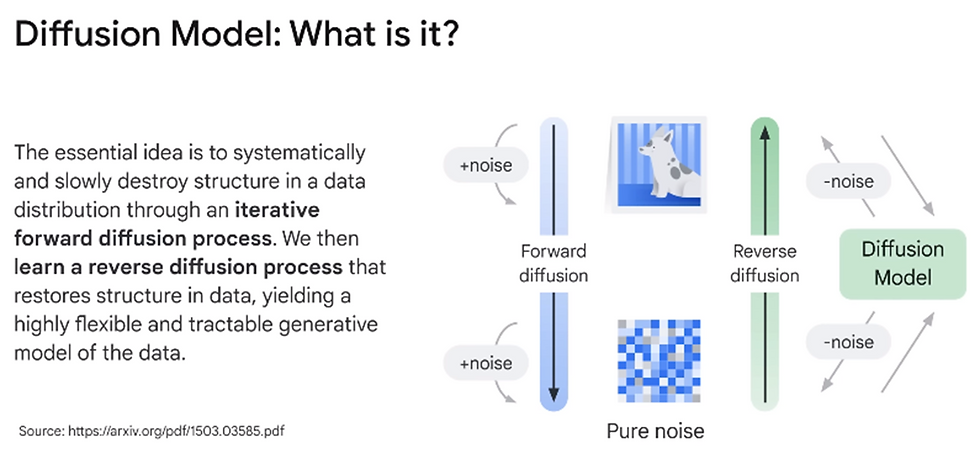
The forward diffusion process systematically and slowly destroys the structure in a data distribution by iteratively adding noise.
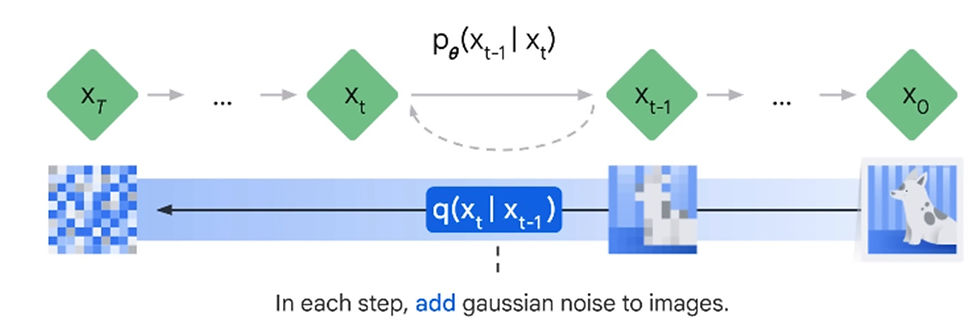
The distribution Q depends only on the previous step, making it a Markov chain.
In the initial research paper, 1000 iterations were used (T=1000) to reach a state of pure noise, effectively obliterating any structure in the original image.
Reverse Diffusion Process
To perform the reverse diffusion process, a machine learning model is trained to predict the noise added at each step.
The model takes in a noisy image as input and outputs a prediction of the noise that was added to it.
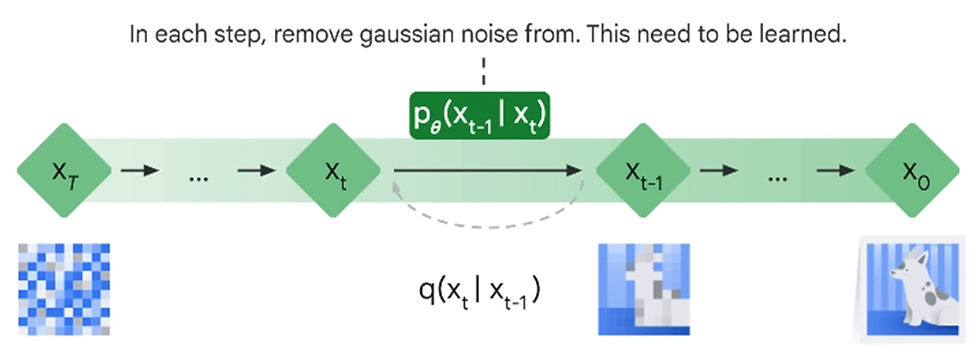
The model is trained using a loss function that measures the difference between the predicted noise and the actual noise, encouraging the model to minimize this difference. [DDPM -> Denoising Diffusion Probabilistic Models]
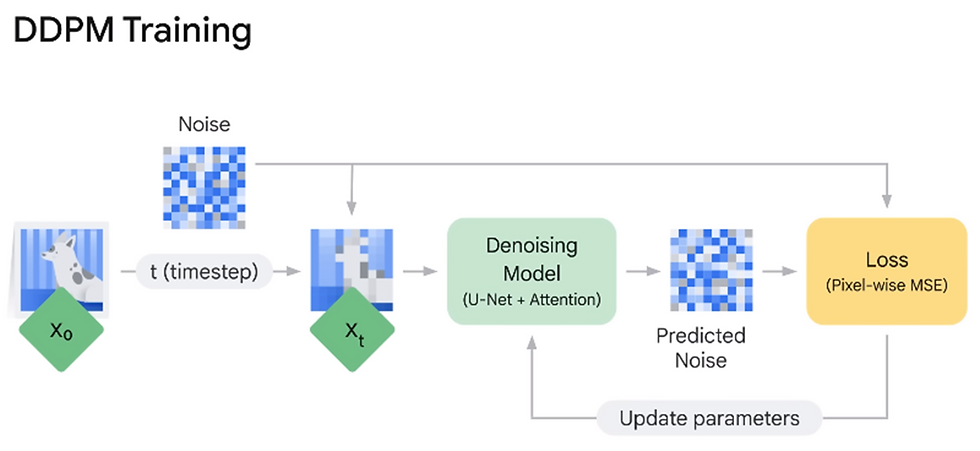
Image Generation
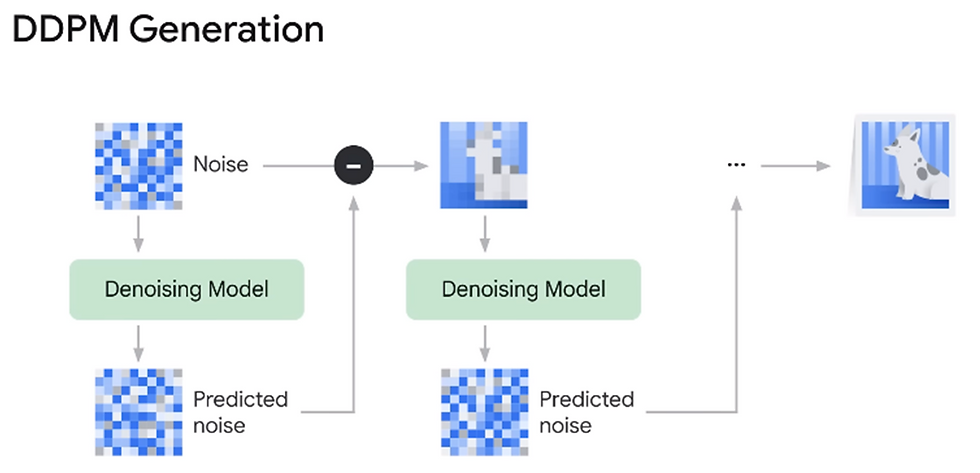
To generate images with a trained diffusion model, start with pure noise and send it through the model.
Subtract the predicted noise from the initial noise at each iteration.
The model learns the real data distribution of images and samples from this distribution to create new, novel images.
4. Recent Advances and Applications
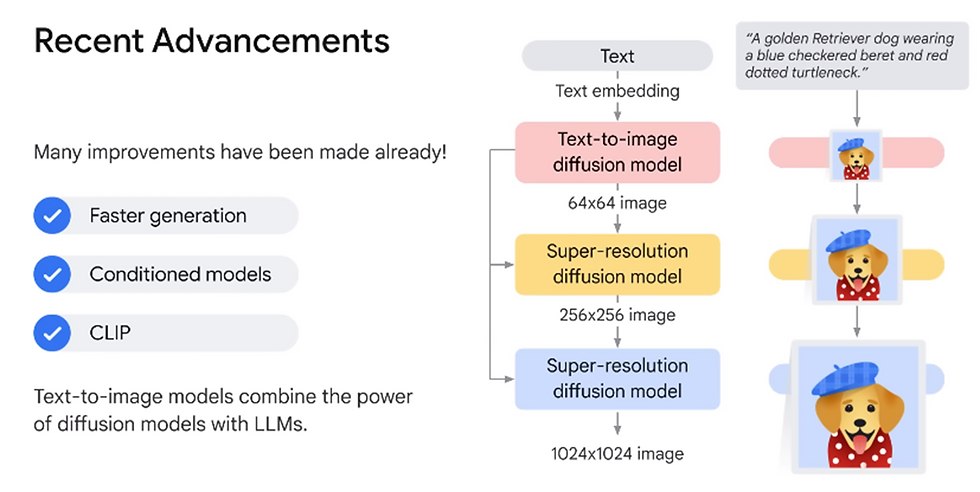
Recent developments in diffusion models have led to faster image generation and more control over the generated images.
The combination of diffusion models with large language models (LLMs) allows for the creation of context-aware, photorealistic images from text prompts.
An example of this combination is Imogen from Google Research, which is a composition of an LLM and several diffusion-based models. The integration of these technologies enables a wide range of applications in enterprise-grade products on platforms like Vertex AI.
Check out the complete video lecture here :
Did you find this useful ?
Yes
No



Comments